Managing Project-Specific Environments With Conda
Getting started with Conda and a minimal set of "best practices" for daily use.
Getting Started with Conda
Conda is an open source package and environment management system that runs on Windows, Mac OS and Linux.
- Conda can quickly install, run, and update packages and their dependencies.
- Conda can create, save, load, and switch between project specific software environments on your local computer.
- Although Conda was created for Python programs, Conda can package and distribute software for any language such as R, Ruby, Lua, Scala, Java, JavaScript, C, C++, FORTRAN.
Conda as a package manager helps you find and install packages. If you need a package that requires a different version of Python, you do not need to switch to a different environment manager, because Conda is also an environment manager. With just a few commands, you can set up a totally separate environment to run that different version of Python, while continuing to run your usual version of Python in your normal environment.
Conda? Miniconda? Anaconda? What’s the difference?
Users are often confused about the differences between Conda, Miniconda, and Anaconda.
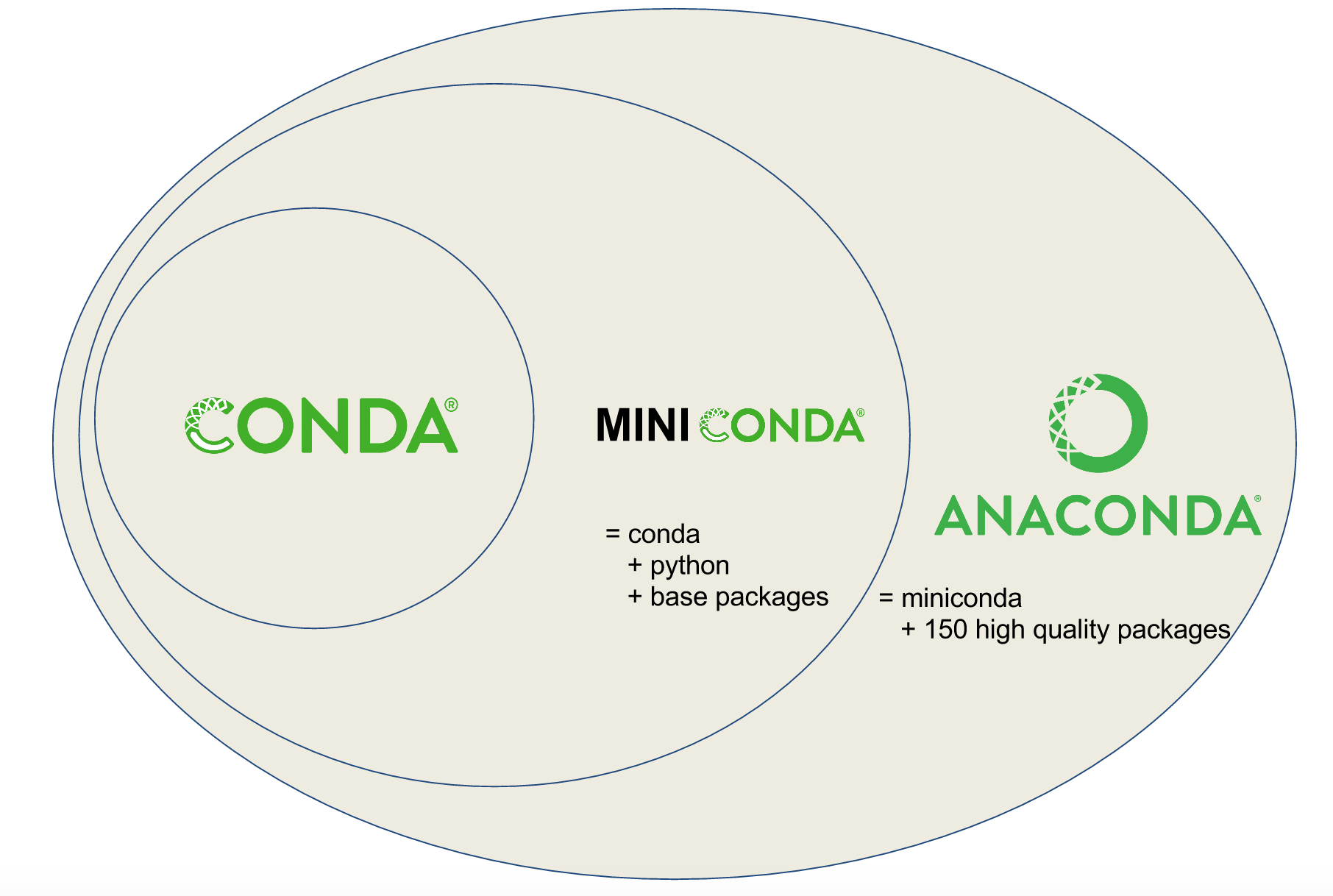
I suggest installing Miniconda which combines Conda with Python 3 (and a small number of core systems packages) instead of the full Anaconda distribution. Installing only Miniconda will encourage you to create separate environments for each project (and to install only those packages that you actually need for each project!) which will enhance portability and reproducibility of your research and workflows.
Besides, if you really want a particular version of the full Anaconda distribution you can always create an new conda environment and install it using the following command.
conda create --name anaconda202002 anaconda=2020.02
Installing Miniconda
Download the 64-bit, Python 3 version of the appropriate Miniconda installer for your operating system from and follow the instructions. I will walk through the steps for installing on Linux systems below as installing on Linux systems is slightly more involved.
Download the 64-bit Python 3 install script for Miniconda.
wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
Run the Miniconda install script. The -b runs the install script in batch mode
which doesn’t require manual intervention (and assumes that the user agrees to
the terms of the license).
bash Miniconda3-latest-Linux-x86_64.sh -b
Remove the install script.
rm Miniconda3-latest-Linux-x86_64
Initializing your shell for Conda
After installing Miniconda you next need to configure your preferred shell to be “conda-aware”.
conda init bash
source ~/.bashrc
(base) $ # now the prompt indicates that the base environment is active!
Updating Conda
It is a good idea to keep your conda installation updated to the most recent
version.
conda update --name base conda --yes
Uninstalling Miniconda
Whenever installing new software it is always a good idea to understand how to uninstall the software (just in case you have second thoughts!). Uninstalling Miniconda is fairly straighforward.
Uninitialize your shell to remove Conda related content from ~/.bashrc.
conda init --reverse bash
Remove the entire ~/miniconda3 directory.
rm -rf ~/miniconda3
Remove the entire ~/.conda directory.
rm -rf ~/.conda
If present, remove your Conda configuration file.
rm ~/.condarc
Conda “Best Practices”
In the following section I detail a minimal set of best practices for using Conda to manage data science environments that I use in my own work.
TLDR;
Here is the basic recipe for using Conda to manage a project specific software stack.
(base) $ mkdir project-dir
(base) $ cd project-dir
(base) $ nano environment.yml # create the environment file
(base) $ conda env create --prefix ./env --file environment.yml
(base) $ conda activate ./env # activate the environment
(/path/to/env) $ nano environment.yml # forgot to add some deps
(/path/to/env) $ conda env update --prefix ./env --file environment.yml --prune) # update the environment
(/path/to/env) $ conda deactivate # done working on project (for now!)
New project, new directory
Every new project (no matter how small!) should live in its own directory. A good reference to get started with organizing your project directory is Good Enough Practices for Scientific Computing.
mkdir project-dir
cd project-dir
New project, new environment
Now that you have a new project directory you are ready to create a new environment for your project. We will do this in two steps.
- Create an environment file that describes the software dependencies (including specific version numbers!) for the project.
- Use the newly created environment file to build the software environment.
Here is an example of a typical environment file that could be used to run GPU accelerated, distributed training of deep learning models developed using PyTorch.
name: null
channels:
- pytorch
- conda-forge
- defaults
dependencies:
- cudatoolkit=10.1
- jupyterlab=1.2
- pip=20.0
- python=3.7
- pytorch=1.4
- torchvision=0.5
Once you have created an environment.yml file inside your project directory
you can use the following commands to create the environment as a sub-directory
called env inside your project directory.
conda env create --prefix ./env --file environment.yml
Activating an environment
Activating environments is essential to making the software in environments work well (or sometimes at all!). Activation of an environment does two things.
- Adds entries to
PATHfor the environment. - Runs any activation scripts that the environment may contain.
Step 2 is particularly important as activation scripts are how packages can set arbitrary environment variables that may be necessary for their operation.
conda activate ./env # activate the environment
(/path/to/env) $ # now the prompt indicates which environment is active!
Updating an environment
You are unlikely to know ahead of time which packages (and version numbers!) you will need to use for your research project. For example it may be the case that…
- one of your core dependencies just released a new version (dependency version number update).
- you need an additional package for data analysis (add a new dependency).
- you have found a better visualization package and no longer need to old visualization package (add new dependency and remove old dependency).
If any of these occurs during the course of your research project, all you need
to do is update the contents of your environment.yml file accordingly and then
run the following command.
conda env update --prefix ./env --file environment.yml --prune # update the environment
Alternatively, you can simply rebuild the environment from scratch with the following command.
conda env create --prefix ./env --file environment.yml --force
Deactivating an environment
When you are done working on your project it is a good idea to deactivate the
current environment. To deactivate the currently active environment use the
deactivate command as follows.
conda deactivate # done working on project (for now!)
(base) $ # now you are back to the base environment
Interested in Learning More?
For more details on using Conda to manage software stacks for you data science projects, checkout the Introduction to Conda for (Data) Scientists training materials that I have contributed to The Carpentries Incubator.